大家好,媛子又出没在精品案例了。(已接收到熊大转达的熊孩子抗议信号,将很快回归多元剑法版块……)
本次案例,在媛子的同事——集才华美貌于一身的晖晖老师的大力支持下,指(zhe)导(mo)集才华身高于一身的小鲜肉一枚,在集美景高温于一身的厦门,顺利完工。请各位看官笑纳。
在这个三岁小孩都嚷嚷着要玩手机的年代,手机里没几个像样的APP都不好意思跟人家打招呼。然而,很多手机小白在选择APP时,要么简单粗暴地选择“装机必备”的APP下载,要么像小编一样坚信“群众的眼睛是雪亮”的,认准下载量或者注册用户最多的APP,不管三七二十一,就决定是你了,皮卡丘……(咳咳,走错片场了)。一直以来,小编都自诩这个方法最靠谱,直到听说用户流量是可以购买的!(崩溃脸)在各式各样如海洋般的APP中,小编就一下子找不着北了。难道,对于可恶的虚假用户、虚假流量,我们真的束手无策了吗?

虚假用户扰乱我们这些潜在用户的下载判断,对于APP开发商来说更是“一生恨”:根据维基百科的数据,截至2017年,苹果App Store中应用数目已经超过2,200,000,而Google Play中应用数目则超过2,700,000。
在这一庞大基数的背后,应用开发者面临着极其激烈而残酷的竞争。由此应运而生的,则是一个新兴的行业:应用市场优化ASO(App Store Optimization),其主要任务推广APP,吸引更多用户注册,提高APP市场占有份额。但是承担ASO优化的代理商有时会通过使用虚假用户造成推广假象,从APP开发商获得高额利润。
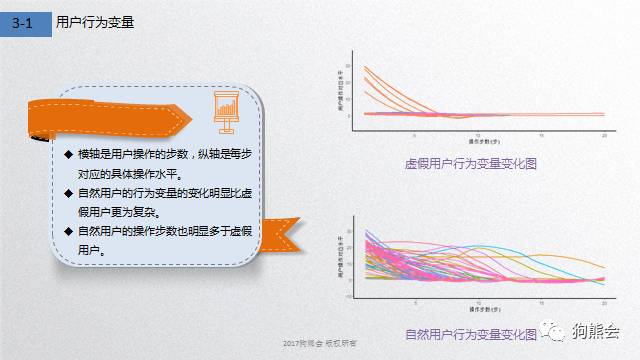
为了识别虚假用户,我们使用某APP市场咨询公司的用户数据——包括了刻画用户在APP上操作情况的用户行为变量、用户访问网页数、用户开始使用APP的方式以及用户访问的时长等,加入人为噪音,并对其进行分析。

通过初步的描述统计,我们可以发现,自然用户的行为变量的变化明显比虚假用户更为复杂;自然用户的操作步数也明显多于虚假用户。
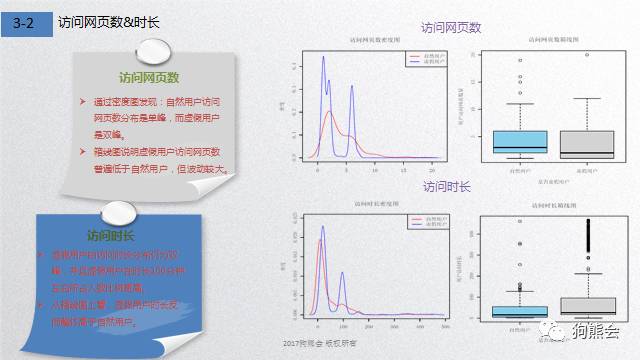
在用户访问页数上,自然用户访问网页数分布是单峰,而虚假用户是双峰。箱线图说明虚假用户访问网页数普遍低于自然用户,但波动较大;在用户访问时长上,虚假用户的访问时长分布仍为双峰,并且虚假用户在时长100分钟左右所占人数比例更高。而从箱线图上看,虚假用户时长反而整体高于自然用户。
至于用户开始方式,由于开始方式和用户类别均为名义变量,我们可使用列联表分析判断二者独立性,结果说明不同用户的打开方式具有显著不同。

初步描述分析后,我们知道用户行为变量、访问页数等变量与是否虚假用户有着千丝万缕的关系,可是具体什么关系,关系的强弱和作用方式就需要我们做进一步的量化分析了。
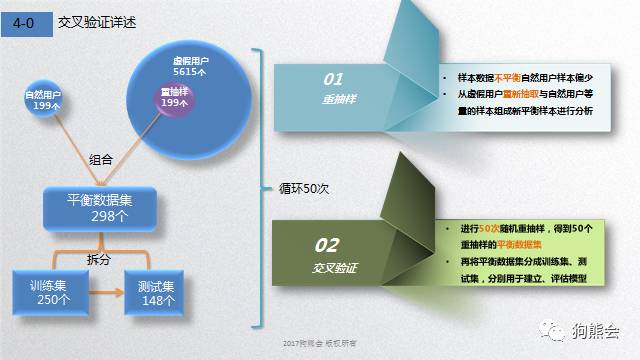
由于数据集中虚假用户和自然用户数目相差很大,所以如果你想直接代入数据跑模型,那就图样图森破了。我们首先要根据交叉验证重复抽样得到平衡数据,然后才能用市面上经常见到的0-1回归或神经网络、SVM支持向量基等或简单易行或不明觉厉的判断方法。
使用模型预测准确度ACC和分类问题逃不开的AUC(ROC曲线下面积)作为评价标准,神经网络优于0-1回归和SVM支持向量基,所以案例中我们只呈现了神经网络的结果——先根据经验公式算出隐层大概的节点数目,再此基础上不断尝试可能的节点数建模,直到找出最优的拟合模型(此处省去一万字Ծ‸Ծ)。

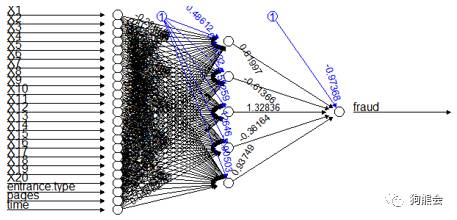
上图水妈看到必大笑三声:又为我的丑图百讲贡献素材了!所以机智的我们悬崖勒马,只呈现系数较大的节点,并且使用不同的颜色表示变量到隐层不同的节点,呈现了如下小清新的Look——根据权重数值大小不难看出,判断虚假用户的主要依据是节点1和4,二者又受行为变量和开始方式等解释变量的影响。
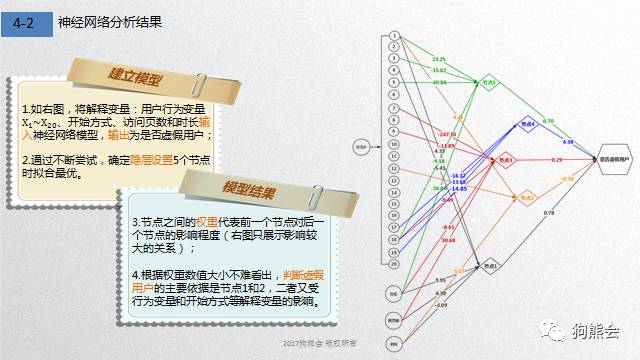
根据最终的模型,我们可以用来判断一个用户是否为虚假用户。在能准确预测虚假用户的前提下,我们就能实现精准营销,根据提取的自然用户特征,有针对性地投放广告;与此同时,我们也能根据虚假用户的特征,开发识别或是屏蔽虚假用户的软件,从此与“僵尸粉”say byebye。

想了解更多案例详情,请加入狗熊会高校会员,详情咨询王老师(电话,邮箱xuan. )。
媛子小分队成员:黄明亮、晖晖老师、媛子、刘天赐、樊金麟返回搜狐,查看更多
- 本文固定链接: https://douyinkuaishou.cc/?id=1652
- 转载请注明: admin 于 抖音快手 发表
《本文》有 0 条评论