近年来,短视频成为移动互联网全速发展的地方,而快手也成为最大的流量收割者之一。
据统计,2018年,快手短视频App日活达到2亿人次,日播放量达200亿;大约每7个中国人中就有一个快手的内容生产者,日均新增作品超过1500万个;同时,有1600多万人通过快手App获得收益,总体收超过200亿。
自2011年成立以来,快手从一个Gif生成工具一跃成为日活最高、最赚钱的短视频内容社区之一,并且相继得到百度、腾讯等互联网巨头、头部内容平台的投资,其发展速度令人咋舌。
而作为新一代视频平台,快手的AI“黑科技”也贯穿于其内容、分发、互动的各个环节,令人想要一探究竟。
近日,智东西来到快手总部,有幸探访到了快手异构计算架构师钟辉,并向他了解到了这家“国民级视频社区”背后的AI技术应用及英特尔为其提供的硬核“装备”。钟辉的电脑屏幕上显示着“距离春节2020年春节38天”的倒计时,这对他来说就像“高考倒计时”。据了解,快手上个月刚刚中标了2020年央视春晚独家互动合作伙伴。

很多“快手”用户都能体验到,快手APP中有许多酷炫的视频特效和包装功能,这也是快手AI“炫技”的一大窗口。
在记录和生产体验方面,“梵高”特效中的场景语义分割、“雷神”中的手势识别、国内首创的“智能剪影”、不挑手机配置的“变童颜”特效中的移动终端实时GAN等都是自主研发。

在消费互动体验方面,其视频的增强、转码、播放、渲染以及直播和游戏服务都涉及多个环节不同的智能技术,比如将720P视频提升到1080P的超分算法等。
从内容方面来说,快手在内容安全、原创保护和视频配音等侧重方面有一套自己的“多模态内容理解”逻辑。
具体来说,快手使机器提取用户上传的文本、图像、音频中的特征,通过知识图谱、语义理解、分类检索的技术来为视频配上跌宕起伏的音乐、审核内容是否涉及黄赌毒、判别内容是否山寨其它的网红视频等。

快手相关负责人告诉智东西,快手更加致力于通过机器学习、强化学习、图表达学习等技术手段践行“普惠”价值观。
具体来说,通过全新一代推荐系统,快手一方面采用“基础曝光+爬坡”的机制,使得所有用户的内容既能得到关注,又能沉淀出精品;另一方面,利用“基尼系数”来平衡流量分配,适当将大主播的流量分配给长尾用户,从而减弱流量维度的“贫富差距”。

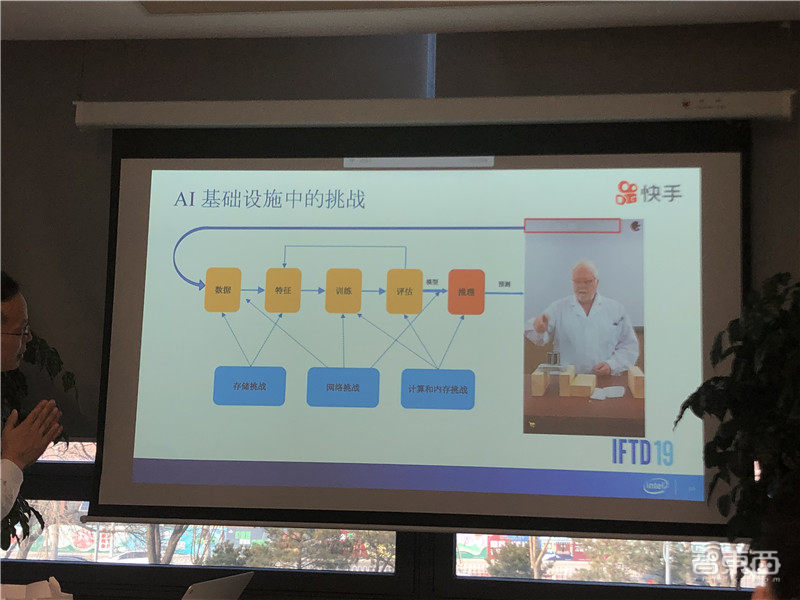
AI和大数据驱动,体现在快手从“内容生产”到理解、分发、消费、互动的各个环节。作为一家主打短视频/直播的全民性社区,快手的AI应用的数据中心在存储、网络、计算三个方面面临巨大挑战。
快手异构计算架构师钟辉说:“一方面,日均新增超1500万作品,内容数据、行为数据、以及由数据特征提取带来巨大存储挑战;另一方面,在训练和推理当中因为特征参数越来越多,导致模型变得越来越大,由此带来这些数据在网络当中传输的挑战。再加上每天千亿级的展示,这当中也带来了计算和内存挑战。”
近年来,CPU性能提升已经遇到了明显瓶颈,每年仅提升约3%,但是数据的增长率却达到30%,所以供需之间有一个巨大的缺口,异构计算应运而生。
在加速器上,快手选择英特尔的FPGA产品加持其数据中心。FPGA是可编程的器件,具有灵活、低延迟的特点,正好契合快手快速发展的AI模型、算子。
钟辉说:“相比于GPU,FPGA更适用于线上强调实时推理的应用场景,并且在数据中心,FPGA是有网口的,而GPU是没有的,所以有一些任务GPU是不擅长做的。”

钟辉介绍,快手异构平台分为三大类,分别是基于英特尔A10、E3S10和PAC S10的器件。
以A10为例,它的峰值算力可以达到1.366TFLOPS,它也有一列列的片上的SRAM,这就构成了片上的分布式存储,可以提供6MB的SRAM;区别于CPU和GPU,它的片上的SRAM是分布式的,所以它可以提供高达8TB/s的并行带宽,非常满足深度学习模型的需求。

另外,A10也有片外的DDR,从接口来说,它提供了PCIe的接口,可以以加速卡的形式插在服务器上,构成一个异构计算系统。
同时,A10的网络接口也是GPU所没有的。从开发工具来说,传统的FPGA开发有一个非常大的问题,那就是开发周期非常长,现在英特尔推出了OpenCL的开发语言降低了开发难度,虽然还不能像软件一样去做硬件,但是对于有一定硬件背景设计人员来说,开发难度和周期可以明显降低。
钟辉说:“另外一个很有意思的是英特尔E3S10,这个大加速卡上面是E3的CPU,视频编解码能力非常强,因为它里面还有专门的GPU。然后,再加上S10的FPGA,就构成了一个比较齐全的异构加速卡。”
钟辉接着介绍了快手基于OpenCL的开发案例:“我们在数据中心部署FPGA,面临‘上天’和‘入地’两个方面的挑战。”
“上天”是说FPGA是部署在云上的,因此快手团队首先要提高业务服务容量,充分利用FPGA来降低线上服务延时,同时像开发软件一样去交付硬件,从而实现高速的业务迭代;“入地”则谈的是部署,则要求成本可担负、具有稳定性且能耗更低,另外,还需要规模化、容器化部署,以解决资源的弹性部署。

以DRN(Deep Ranking Network)加速为例,当时商业化部门的排序网络在业务高峰期出现了抖动,需要采用异构方案来做加速。考虑到其中以计算为主的工作负载占到了CPU负载的50%,所以团队把计算这一块Off-loading到FPGA上去。
在硬件设计上,团队通过矩阵乘法将算法映射到FPGA的阵列结构上。但是,由于用了上千个乘法单元,运行达到几百兆,DDR根本无法满足。所以团队就采用了Systolic Array(脉动阵列)结构,把输入数据放到分布式的SRAM上,从而提供了这个应用要求的算力和带宽,同时降低了功耗。

钟辉说:“我们可以看到,相比于CPU方案,延迟降低了约1.5倍,最大吞吐大概提升了1.7倍左右,功耗有接近5倍的降低,从功耗效率来说提升了近8倍。这个我们已经在数据中心当中规模化的部署了,这是我们商业化的一个业务场景。从FPGA在数据中心落地的角度来讲是比较领先的。”

长期以来,社交媒体平台一直不算走在AI技术舞台的中心,但通过此次的实地探访,我们发现这家“国民级”短视频公司的AI技术似乎比我们从App表面上看到的要深入得多。
在快手AI应用背后,日均新增超1500万作品、千亿级的展示、越来越大的算法模型都为存储、传输和计算带来了巨大的挑战,对此,快手选择英特尔CPU、FPGA支持的“异构计算”器件来加以应对,从而实现了延迟、功耗效率的极大优化。
随着AI技术渗透到各行各业,社交媒体行业的AI化也深入到内容生成、内容分发、用户互动、引导消费等各个环节。计算力是AI发展的三大要素之一,很多企业已有成熟的算法和更充分的数据,这时利用异构计算等技术来提升算力也成为一大关键举措。返回搜狐,查看更多
- 本文固定链接: https://www.douyinkuaishou.cc/?id=16111
- 转载请注明: admin 于 抖音快手 发表
《本文》有 0 条评论